



Opis problemu
Niska jakość powietrza stanowi w Polsce poważny problem zwłaszcza na terenie dużych aglomeracji miejskich. Jako jednego z głównych winowajców takiego stanu rzeczy wskazuje się tzw. kopciuchy, czyli piece ogrzewane paliwem stałym. Zespół badawczy LAB/opegieka, zaangażowany w poszukiwanie niekonwencjonalnych rozwiązań w analizach przestrzennych, sprawdził jak uczenie maszynowe może przyczynić się do walki ze smogiem. W ramach prac badawczo-rozwojowych przetestowaliśmy algorytmy umożliwiające identyfikację obiektów wyposażonych w piece ogrzewane paliwem stałym, które w sezonie grzewczym mogą stanowić źródło nawet 90% stężenia pyłu PM10.
Do implementacji rozwiązania wykorzystano publicznie dostępne zobrazowania teledetekcyjne oraz wewnętrznie przygotowane algorytmy uczenia maszynowego.
Z niniejszej publikacji dowiesz się:
- jak wygląda proces identyfikacji obiektów ogrzewanych paliwami stałymi z wykorzystaniem algorytmów uczenia maszynowego;
- o czym należy pamiętać, by z wykorzystaniem wspomnianych technik stworzyć efektywną alternatywę dla manualnych analiz przestrzennych.
Dane
Tworzenie bazy budynków ogrzewanych paliwem stałym możliwe jest dzięki przeprowadzeniu analizy sadzy na dachach budynków. Jednakże dane, aby mogły być wykorzystane w celach analitycznych, muszą spełniać określone kryteria. Kluczowe jest, żeby nalot, z którego pochodzą użyte dane teledetekcyjne był wykonany w okresie grzewczym. Co więcej, zobrazowania muszą charakteryzować się odpowiednio wysoką rozdzielczością przestrzenną. Na potrzeby poniższej analizy przyjęto, że zdjęcia o wielkości piksela równej 5 cm zapewnią optymalne rezultaty.
Poniższa grafika przedstawia przykłady budynków dla następujących klas:
a) budynki ogrzewane paliwem stałym;
b) pozostałe budynki.

Oczywiście istnieją przykłady kominów, dla których użytkownik nie jest w stanie określić stosowanego sposobu ogrzewania. Wobec tego, by przeprowadzić badania możliwości klasyfikacji i detekcji sadzy przeprowadziliśmy analizy na danych pobranych z geoportalu Jastrzębie Zdrój. Wykorzystane dane przestrzenne obejmują nie tylko ortofotomapę, ale również precyzyjną informację na temat źródła niskiej emisji.
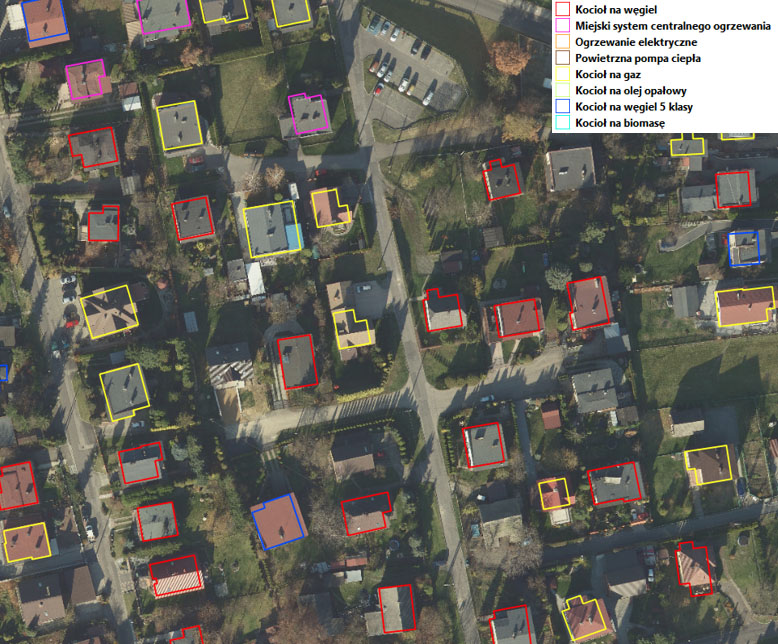
Rys. Fragment ortofotomapy z wektorem źródeł niskiej emisji.
Źródło: http://mapa.um.jastrzebie.pl/mapa.html
Powyższe dane posłużyły do stworzenia zestawu treningowego dla budynków przyporządkowanych do dwóch klas:
1 - budynki ogrzewane paliwem stałym;
0 - pozostałe budynki.
Model klasyfikacji budynków
Na podstawie właściwie przygotowanych danych możliwe jest tworzenie modelu uczenia maszynowego. W omawianym przykładzie do analiz wykorzystano intuicyjną bibliotekę Python służącą do tworzenia sieci neuronowych – Keras. Na początku dane poddano wstępnemu przetwarzaniu, przycięto je do rozmiaru 299x299 pikseli, znormalizowano wartości pikseli oraz podzielono na zbiór trenujący, walidujący i testowy proporcji: 0,8 : 0,1 : 0,1. Dane na tym etapie są ograniczone i niezbalansowane: spośród 4346 występujących przypadków aż 3277 należy do klasy paliwa stałego.
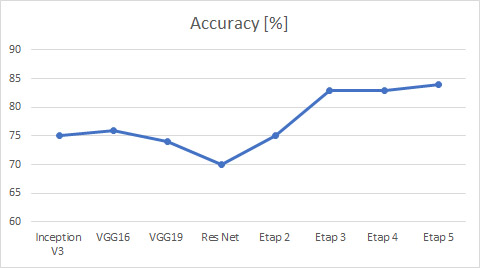
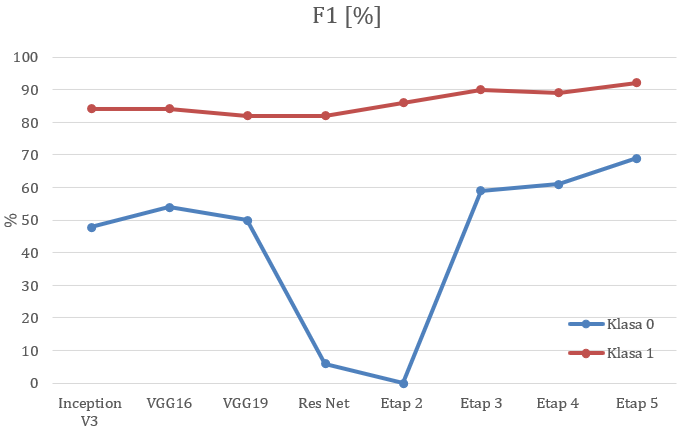
Poniżej przedstawiliśmy kolejne etapy ewaluacji modelu. We wstępie założono funkcję kosztów cross-entropy oraz optymalizator Adadelta. Wyniki osiągnięte dla każdego etapu zostały przedstawione na wykresach, umieszczonych w dalszej części artykułu.
Etapy ewaluacji modelu:
- W pierwszym kroku przetestowano wstępnie wyszkolone modele, np. VGG, InceptionV3 i ResNet. Jest to najprostsza metoda klasyfikacji, która wykorzystuje wyuczone wzorce. Zakłada ona dopasowanie wybranego modelu do podobnego zadania klasyfikującego, jednakże w tym przypadku zadanie ma charakter badawczy, dlatego przetestowano kilka przykładów przeszkolonych modeli. Zastosowana w tym celu metoda Transfer Learningu pozwala na skrócony czas klasyfikacji oraz nie wymaga dużego zbioru danych treningowych.
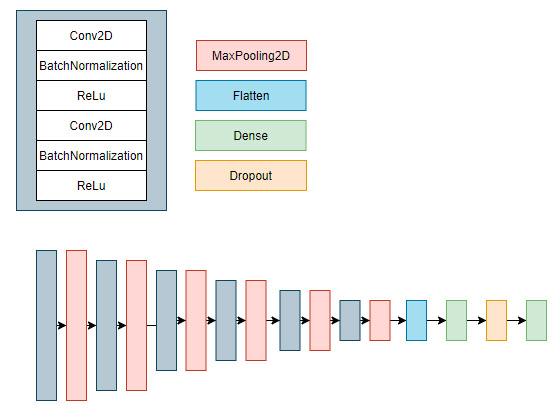
- Następnie sporządzono prostą sieć konwolucyjną, której schemat został przedstawiony poniżej.Klasyfikator ten ma za zadanie rozróżnić zdjęcie dla dwóch klas ze względu na występowanie sadzy.
Dla powyższego modelu klasyfikator przewiduje wyłączenie klasę najczęściej występującą. Dlatego celem kolejnych etapów jest poprawa klasyfikatora i osiągnięcie jak najwyższej dokładności w obrębie obu klas. W kolejnych punktach model bazowy został wykorzystany w celu porównania kolejnych iteracji rozwiniętego modelu. - Wynikiem braku rozróżniania klas w poprzednim etapie było trenowanie modelu na niezbalansowanym zestawie danych. Innymi słowy wśród danych treningowych znalazły się klasy, dla których zbiór był ubogi. Wobec tego uznano konieczność nadania poszczególnym klasom wagi odwrotnie proporcjonalnie do ich wielkości w zbiorze danych.
- Kolejnym etapem istotnym w procesie tworzenia sztucznej sieci neuronowej jest trenowanie sieci na dużym zestawie danych. Ograniczeniem w niniejszym badaniu był fakt posiadania ograniczonego zestawu obrazów. Jednym ze sposobów pokonania takich ograniczeń jest wykorzystanie możliwości zwiększenia zbioru za pomocą augmentacji danych. Wspomniana biblioteka Keras udostępnia funkcję ImageDataGenerator, która pozwala na rozszerzanie danych w locie. Oznacza to, że dane nie zabierają zbędnego miejsca, a jedynie generują przekształcenia podczas dopasowywania modelu.
Spośród wielu możliwości wykorzystano wyłącznie te, które mogły utworzyć obrazy zbliżone o wysokim stopniu prawdopodobieństwa ich wystąpienia w przyszłości. W przypadku klasyfikacji zdjęć lotniczych wykorzystano funkcję dopełnienia danych przy następujących założeniach:
-
dopuszczalny maksymalny kąt obrotu do 90°;
-
dopuszczalne losowe przesunięcie do 20% powierzchni obrazu horyzontalnie lub wertykalnie;
-
dopuszczalne rozjaśnienie od 20 do 80%;
-
dopuszczalne losowe odwrócenie danych wejściowych w poziomie oraz wypełnienie pustych przestrzeni przez odbicie.
-
- Dodatkowo wykorzystano funkcję kosztów focal loss, która pozwoliła na skupienie się na przykładach trudnych do sklasyfikowania. W przypadku danych niezbalansowanych prawdopodobna będzie poprawna klasyfikacja klasy większościowej ze względu na dużą ilość przykładów. Natomiast przy wykorzystaniu funkcji focal loss, możliwe jest położenie większego nacisku również na klasę mniejszości i wzrost dokładności klasyfikacji w obrębie tej klasy.
Wyniki
Istnieje wiele miar, które w sposób ilościowy przedstawiają wydajność modeli. Do podstawowych wskaźników należą precyzja i czułość. Precyzja jest miarą, która spośród wszystkich przewidywań w danej klasie określa procent poprawnie zakwalifikowanych przykładów. Natomiast czułość uwzględnia wszystkie próbki rzeczywiście występujące w danej klasie i określa procent poprawnie przewidzianych przykładów. Różnica pomiędzy powyższymi miarami jest subtelna, choć bardzo istotna. Miary te przedstawiają informacje wyłączenie na temat obszarów, dla których model jest bardziej lub mniej efektywny.
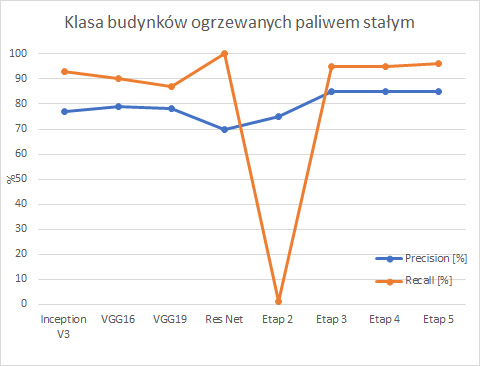
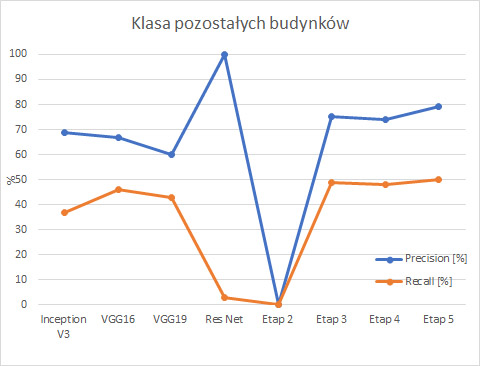
By ogólnie określić, który model jest najlepszym klasyfikatorem należy interpretować dokładność ogólną modelu, która sięga prawie 85%. Nie jest to jednak odpowiednia miara ze względu na niezbalansowany zestaw danych. Wobec tego, współczynnik F1 wydaje się być najbardziej odpowiednią miarą do porównywania modeli, których dane testowe są jednakowo liczne. Miara F1 zawiera w sobie informacje zarówno na temat precyzji, jak i czułości. Wobec tego na powyższych wykresach można zauważyć, że po wprowadzanych zmianach model powoli zwiększa swoją wydajność w obrębie obu klas.
Wnioski
Powyższe testy miały charakter badawczo-rozwojowy, a ich celem była analiza możliwości stworzenia automatycznego algorytmu do wykrywania budynków ogrzewanych paliwem stałym.
- Przeprowadzone badania wydają się potwierdzać przydatność technologii uczenia maszynowego do identyfikacji tzw. „kopciuchów” na ortofotomapie. Dla danych testowych 85% budynków ogrzewanych paliwem stałym zostało poprawnie sklasyfikowanych. Samorządy, na które spadł obowiązek realizacji prac związanych z monitoringiem i wymianą pieców ogrzewanych paliwem stałym, mogą z powodzeniem wykorzystać zaproponowane metody do stworzenia „bazy kopciuchów”.
- Nie każda ortofotomapa może posłużyć do wykonania analizy klasyfikacji pieców ogrzewanych paliwem stałym. Do warunków, które muszą zostać spełnione zalicza się konieczność pracy na danych pozyskanych w sezonie jesienno-zimowym o rozmiarze piksela nie większym niż 5cm.
- Wyżej opisany przykład potwierdza zalety wykorzystywania modeli uczenia maszynowego na potrzeby wielkoskalowych analiz przestrzennych. Właściwie przygotowane algorytmy mogą zapewnić atrakcyjną ekonomicznie i efektywną czasowo alternatywę dla tradycyjnie stosowanych metod manualnych. Warto zauważyć, że przedstawiony wyżej przykład stanowi jedynie wierzchołek góry lodowej, jeśli chodzi o zastosowanie technologii uczenia maszynowego w analizach przestrzennych.
Prace badawcze zostały przeprowadzone przez laureatkę konkursu stażowego „Rozwój kadr sektora kosmicznego” organizowanego przez Agencję Rozwoju Przemysłu i Polski Związek Pracodawców Sektora Kosmicznego.

