



Introduction
Poor air quality, especially within metropolitan areas, has become a serious problem in Poland. Stoves fired by solid fuels are pointed as a main culprit of such situation. Our team committed to searching for an unconventional solutions in the area of spatial analysis has explored the way in which battling the smog could be boosted by the machine learning technology. As a part of the R&D works, we had tested algorithms allowing for identification of an objects equipped with solid fuel stoves, which during the heating season could be a source of up to staggering 90% of the total PM10 dust concentration.
In order to launch the solution, the open-source remote sensing imagery, as well as in-house developed machine learning algorithms had been used.
In the following article you will find out:
- what the process of identifying buildings with solid fuel stoves using the machine learning algorithms looks like;
- what to bear in mind while trying to create an effective alternative for manual spatial analysis.
The data
Creating the database of buildings heated by solid fuel stoves is possible due to conducting analysis of the soot located on the rooftops of the buildings. However, in order to use the data for the analytical purposes it has to meet the certain criteria. The key is to use remote sensing imagery, acquired during the heating season. Moreover, the imagery has to be recorded in high resolution. For the purpose of the following analysis, the 5cm GSD imagery has been adopted and was believed to provide the optimal results.
The image presented below shows some examples of buildings for the following classes:
a) buildings heated by solid fuel stoves;
b) other buildings.

Certainly, there are examples of chimneys, for which identifying the method of heating is infeasible. Therefore, in order to conduct the research of classification and soot detection we have analysed the data downloaded from Jastrzębie Zdrój Geoportal. Spatial data, that had been exploited consists of not only the orthophotomap, but also precise information concerning the low emission source.
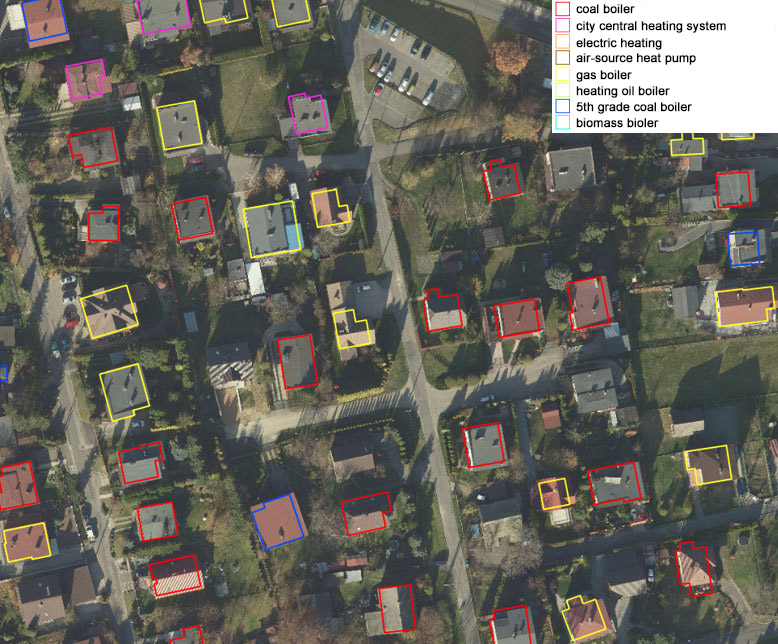
Part of the orthophotomap showing low emission sources.
Source: http://mapa.um.jastrzebie.pl/mapa.html
The aforementioned data has been used to create a training dataset for the buildings assigned to the following classes:
1 - buildings heated by solid fuel stoves;
0 - other buildings.
Buildings classification model
Based on properly prepared data creating the machine learning model is feasible. Keras, the Python library allowing for creating neural networks, has been used in the described example. At first data had been a subject of preliminary processing consisting of resizing into squares of 299x299 pixels, normalising pixels values, as well as dividing into training, validating and testing groups with the following proportions: 0,8 : 0,1 : 0,1. At that point data was limited and unbalanced: 3277 out of 4346 existing cases had been assigned to the solid fuel stoves class.
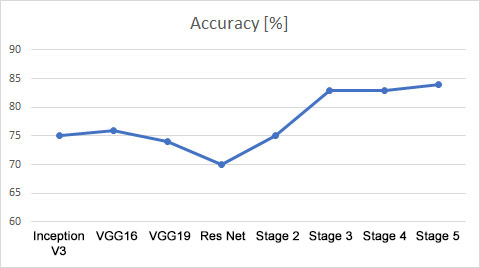
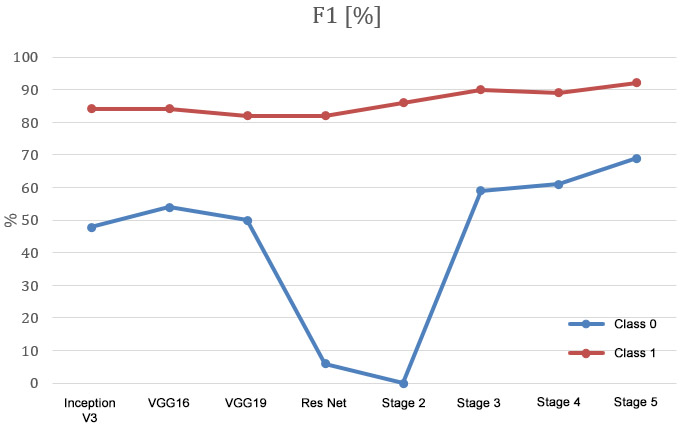
Further stages of the evaluation are presented below. In the introduction, the cross-entropy function has been applied, as well as Adadelta optimiser. The achieved results for each stage had been presented on the charts located in the further part of the article.
The model evaluation stages:
- First step relied on testing the preliminarily trained models, such as VGG, InceptionV3 and ResNet. It is the simplest classification method, which uses learned patterns. Main focus is to match the chosen model with the similar classifying task. However, in this case research is the main purpose of the task, therefore a few trained models had been tested. Using the transfer learning method allowed for shortening the duration of classification and did not require huge training dataset.
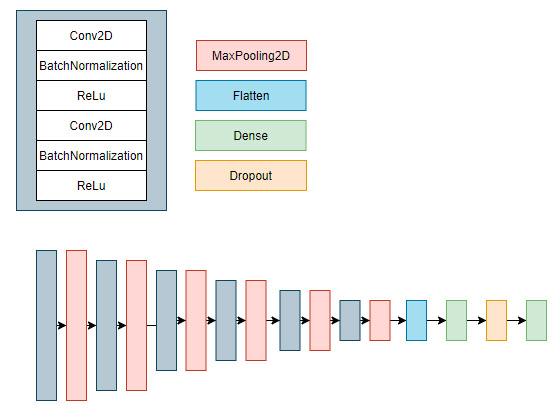
- Then, a simple convolutional network was created, which scheme is presented below. The role of this classifier is to differentiate a photo for two classes concerning occurrence of the soot.
For the aforementioned model, the classifier predicts only the most often occurring class. Thus the aim of the next stages would be enhancing the classifier and achieve as high accuracy as possible within both classes. In the following stages the default model would be used in order to compare the next iterations of the developed model. - The result of not differentiating the classes in the previous step was training the model on unbalanced dataset. In other words, the training dataset contained classes for which collection was poor. Therefore, it was necessary to assign values to the classes inversely proportionate to their size within the dataset.
- The next stage important for the process of creating the neural network is training the network on the great dataset. The obstacle in this research was caused by having the limited set of imagery. One of the method to overcome that obstacle was using the data augmentation in order to enhance the dataset. Aforementioned Keras library offers ImageDataGenerator function, which allows for extending the data on the fly. Thus data do not consume redundant disk space and generate only the transformations while matching the model.
Amongst plenty of possibilities we have chosen only those, which could lead to creating similar images characterised by high probability of occurrence in the future. In case of aerial imagery classification, the function of data complementation has been used. The following assumptions were made:
-
admissible maximum rotation angle up to 90 degrees;
-
admissible random vertical/horizontal shift up to 20% of the image area;
-
admissible brightening from 20 to 80%;
-
admissible random data horizontal flip and filling empty spaces by reflection.
-
- In addition, the focal loss function has been used, which allowed for focusing on samples difficult to classify. In case of unbalanced data, accurate classification of the majority class is highly probable due to the great number of its samples. On the other hand, using the focal loss function ensures stressing also the minority class and increasing the accuracy of the classification within that class.
The results
There are many indicators, that show effectiveness of the model in quantitative way. Precision and accuracy are two of the most commonly used indices. Precision is a measure that determines the percentage of correctly classified cases within a given class. Whereas recall takes into account all the samples actually occurring in a given class and defines percentage of correctly predicted samples. The difference between those indicators is subtle, but significant. They only provide information on the areas for which the model is either more or less effective.
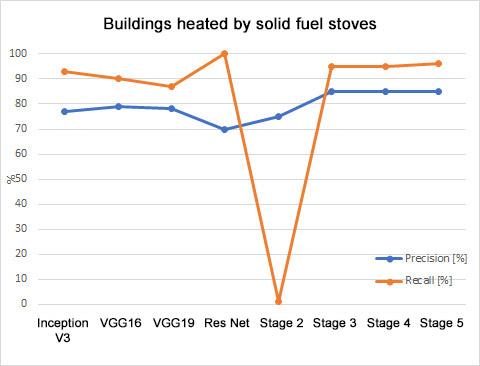
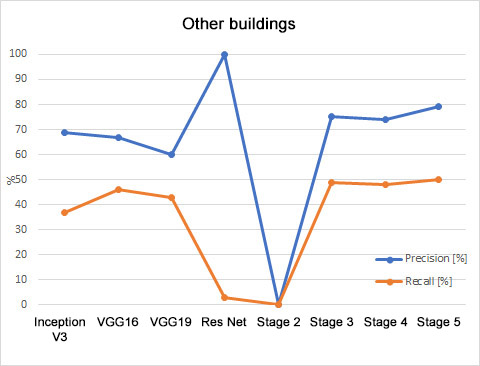
In order to determine which model is the best classifier the general accuracy is the value to be measured. In the described case it has reached almost 85%. However, it is not the most adequate indicator in case of the unbalanced dataset. Therefore, the F1 index seems to be the best suited indicator for the needs of comparing models consisted of the equally numerous test dataset. The F1 index includes both the information about precision and recall. Therefore, on the presented charts show the slight increase of the effectiveness within the both classes after every applied modifications can be observed.
Key takeaways
Aforementioned tests had a R&D nature and their goal was to analyse the possibilities of creating algorithm for detection buildings heated by solid fuel stoves.
- Conducted research seems to confirm usability of the machine learning technology in locating solid fuel stoves on orthophotomaps. For the training data 85% of the buildings heated by solid fuel stoves were correctly classified. Local governments responsible for monitoring and exchanging these stoves, could successfully use describe methods to create a map of solid fuel stoves.
- Not every orthophotomap would be useful in creating such classification. The required criteria includes using the data acquired during the heating season with at least 5 cm GSD.
- Aforementioned example confirms advantages of using the machine learning models for the sake of large-scale spatial analysis. Properly prepared algorithms could ensure commercially viable and time effective alternative for the traditionally used manual methods. It is worth mentioning that the described example is only the tip of the iceberg regarding the practical application of the machine learning in spatial analysis.
R&D works had been executed by the winner of the internship competition “Space Sector Personnel Development” organised by Industrial Development Agency and Polish Space Industry Association.

