



Introduction
The development of classification methods results in the process of traditional methods being replaced by modern and more effective algorithms, e.g. the popular Random Forest model is being displaced by neural networks. Despite the fact those methods grants variety of the new possibilities, they also lay a great number of challenges before the technologists. Neural networks are created according to the idea of a black box model, i.e. the rules of classification remain unknown for the user. With this in mind, it would be impossible to predict, what would be the area within which errors has occurred. In spite of the models classifying the point clouds are currently highly efficient, there still is a necessity of introducing the adjustments. Creating a tool for boosting the classification requires implementation of an reliable means for evaluating the degree of the improvement. The cleaning algorithm apart from the improvement, should aim at lowering the number of actions taken in order to implement manual corrections, as well as redistribution of the points within a class, making the manual edition easier.
In case of both the manual and automated corrections, there is a necessity of evaluating the degree of the improvement. Commonly implemented evaluation metrics, such as an Accuracy or F1 are unreliable in that case. In the case of point clouds of size 5e+6 points, with the preliminary assumption that 3e+4 are incorrectly classified samples, the accuracy level reached 0.994. After successful correction of the error (to 15e+3), the accuracy has raised to 0.997. As far as the accuracy has changed insignificantly, the change in the amount of cleaned samples shifted by more than a half. Besides, we do not have any additional information regarding the type of an error.

As part of developing the methods connected with the testing, we have been analysing what types of errors occur in the classification and during the process of improving the quality of the classification. We have developed the approach consisting of analysing the change in the affiliation at the level of groups of points located nearby. As a result we have designated 5 types of errors.
Algorithm
The first step consisted of designating the errors of the referential classification, prediction and the prediction after being automatically corrected. For designating clusters we have used the algorithm based on volatility in spatial density of the points – DBSCAN.
Neps (p) = {q ∈ D : d(p,q) < ε }
ε -area of searching the nearest neighbour,
p - the core point,
q - the epsilon distance relative to the core point
DBSCAN assigns separate segments for points located in the distance greater than the value, which allows for designating concentrated groups of points without the application of stand-off points.
| Error description | Scheme | |
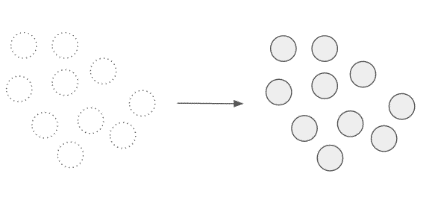
| Type 1. |
All points were the corrected by the classifying algorithm. As a result every point has been assigned to the expected class.
|
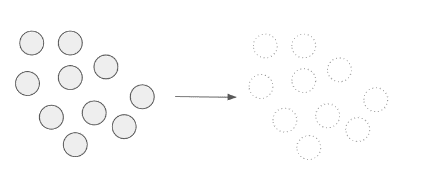 |
| Type 2. |
Number of points in the error segment has not changed – cleaning did not make any impact. The number of points in the error segment has not been changed.
|
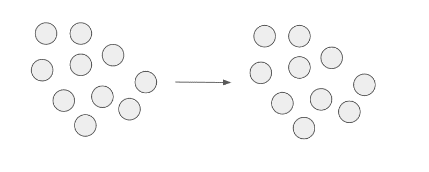 |
| Type 3. |
That type of an error is based on correcting some of the points, so that it was removed from the error segment. Existing segment has been reduced by the number of corrected samples.
|
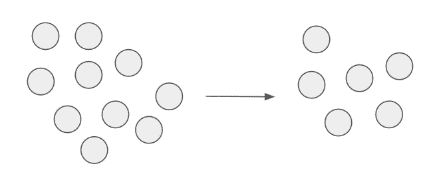 |
| Type 4. |
The number of points has changed, with no benefit – the new segments has been created. The algorithm has incorrectly identified the points that were correctly classified in the first place.
|
 |
| Type 5. |
The error segment has not been neither corrected nor extended by the additional incorrectly classified points. The algorithm thus has incorrectly assign the class for those points during the process of cleaning the classification.
|
 |
Summary
The approach of analysing changes in the number of error segments simplifies the analysis of the classification corrections impact on the final result and shape of classified point cloud. The method provides information on the way of changing the form of occurring errors by the cleaning algorithm.

